Keras with Tensorflow - How to flush CUDA Memory
As a young researcher working in the field of machine learning, I am on a regular basis utilizing GPUs to train different kinds of neural networks such as convolutional neural networks to tackle various problems. In the majority of cases, my tool-of-choice Keras library with Tensorflow backend, which has lovely support for multi-GPU training.
A lot of my work consists of experimenting with various unconventional approaches to train deep neural networks, and with a huge amount of experiments comes along quite a lot of failures. Testing out different experimental settings, I find myself regularly terminating the started Python process if I am not satisfied with the progression of the training or if I notice behavior that was not expected.
And here comes the catch.
I am executing the Python scripts from the terminal and the most straight forward way to terminate the ongoing process is to press Ctrl-C combination to interrupt the process. That would be all good, if there would not be a problem of CUDA not releasing the memory of a terminated python process, which after a few repetitive interruptions of the training scripts takes all the CUDA or GPU memory. And I am not talking about a few hundred megabytes of memory, I am talking about almost a dozen gigabytes of memory per GPU, and I have three of such GPUs. Since the greedy algorithm for distributed training is allocating as much as possible amount of RAM. Such behavior can be detected using the fuser command, in our case the command displaying the not terminated processes would look like this: sudo fuser -v /dev/nvidia* and the output would look similar to the Figure 1.
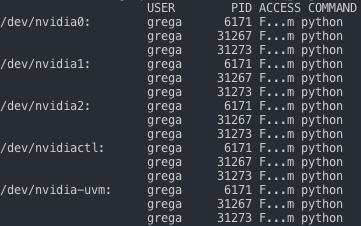
fuser command.To resolve the mentioned issue and to release the allocated RAM after the process being interrupted, the first thing you can try is executing the nvidia-smi --gpu-reset command and checking again with the fuser command if it is resolved the issue. If not, take a look at the PID column of the command output and manually kill the processes with the kill command. In our case, such a command would look like this: sudo kill -9 6171. Repeat the process until the fuser command output is empty, and you are ready to run those experiments again.
Bonus tip.
A lot of times I find myself using the DataImageGenerator, which is quite a handy class allowing us to easily apply the image augmentation on the fly, with a lot of built-in pre-processing features. Using the mentioned class, we are also faced with the increased processing complexity, which in most cases turns out to be the bottleneck in the whole training process. We can overcome this with the utilization of the workers and use_multiprocessing parameters in fit_generator function. Setting the workers parameter to a higher number and enabling the use_multiprocessing usually fixed the problem. But careful! In my experience, the use of the mentioned parameters with the combination of pre-mature termination of the running process with the Ctrl-C shortcut also often results in hanging the python process. So, we are again left with a bunch of processes to kill them manually. My advice, in this case, would be to comment out the used workers and use_multiprocessing parameters when you are in the phase of developing the experiments and enable them when you are conducting final runs of experiments.
That is it! In the comments below, let me know, what kind of problems are you facing when developing new machine learning experiments? How do you tackle them?
Grega Vrbančič
Assistant Professor
Grega Vrbančič is an Assistant Professor at the University of Maribor, Faculty of Electrical Engineering and Computer Science.